Overall, you have to compress monkey brainwaves 200x losslessly to win, but also under severe minihardware constrictions. I doubt anyone is compressing the heavy amount of noise in that 200x, and to the exact hardware specifications of the neuralink, but people did the boring challenge, and its fun to try compression from scratch, so I'm attepmting to compress it on my laptop, and beat the zip baseline.
On a side note though, a fun thought that comes from asking my sister how to compress monkey thoughts:
just make it think stupider
It makes you realize that Elon probably has monkey ELO rankings, and his random data drop probably has the top 5% of monkey thoughts and the worst 5% of monkey thoughts, and the intelligence is all in the wave structure and spikes, not the size, which is also probably why humanity has civilization rather than whales and elephants. "brain scaling laws" are not in the places we look for them
the avg thot is 192kb, overall of ~143mb in the whole dataset, and is probably the entire spread of elons monkeys, cause if anyone is cracked enough to make that moonshot, elon is not about to watch it burn because it wont compress enough on some brainwaves/
I'm going two really simple strats, both arent really production level compressions, but efficiently compress and show the concepts
for context, I got all the binary values of all the files added up and placed in one giant text file so the code behind this is simple enough to be understood by anyone who has manipulated a string and touched python, so the text file made each bit a byte, putting us at 143*8 ~= 1.1gb
In the large single value groups, when ever a string like 00000000000001 shows up, it could be
(13x0)1 instead.
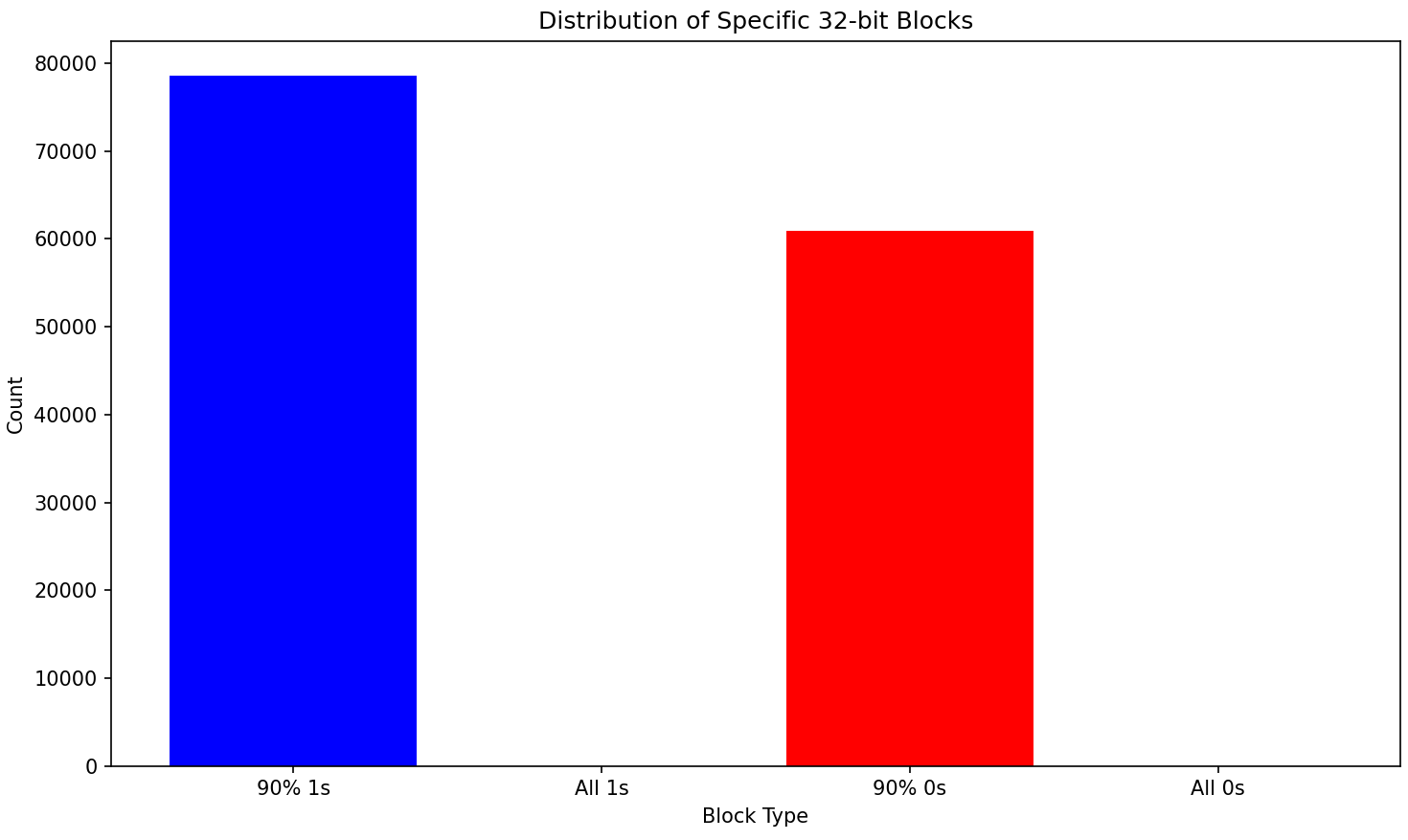
Looking for groups where 90%+ of the block is a single consecutive number gives good results, there are a huge number of blocks that are compressible (more than 9 of the same consecutive values)
using just that, we have a 15% reduction in size, losslessly.
In tokenization, we find the X most common groups of bytes, and compress them to a byte place holder, like a letter or hex
heres some graphs for the most common bytes (1,2, and 4)
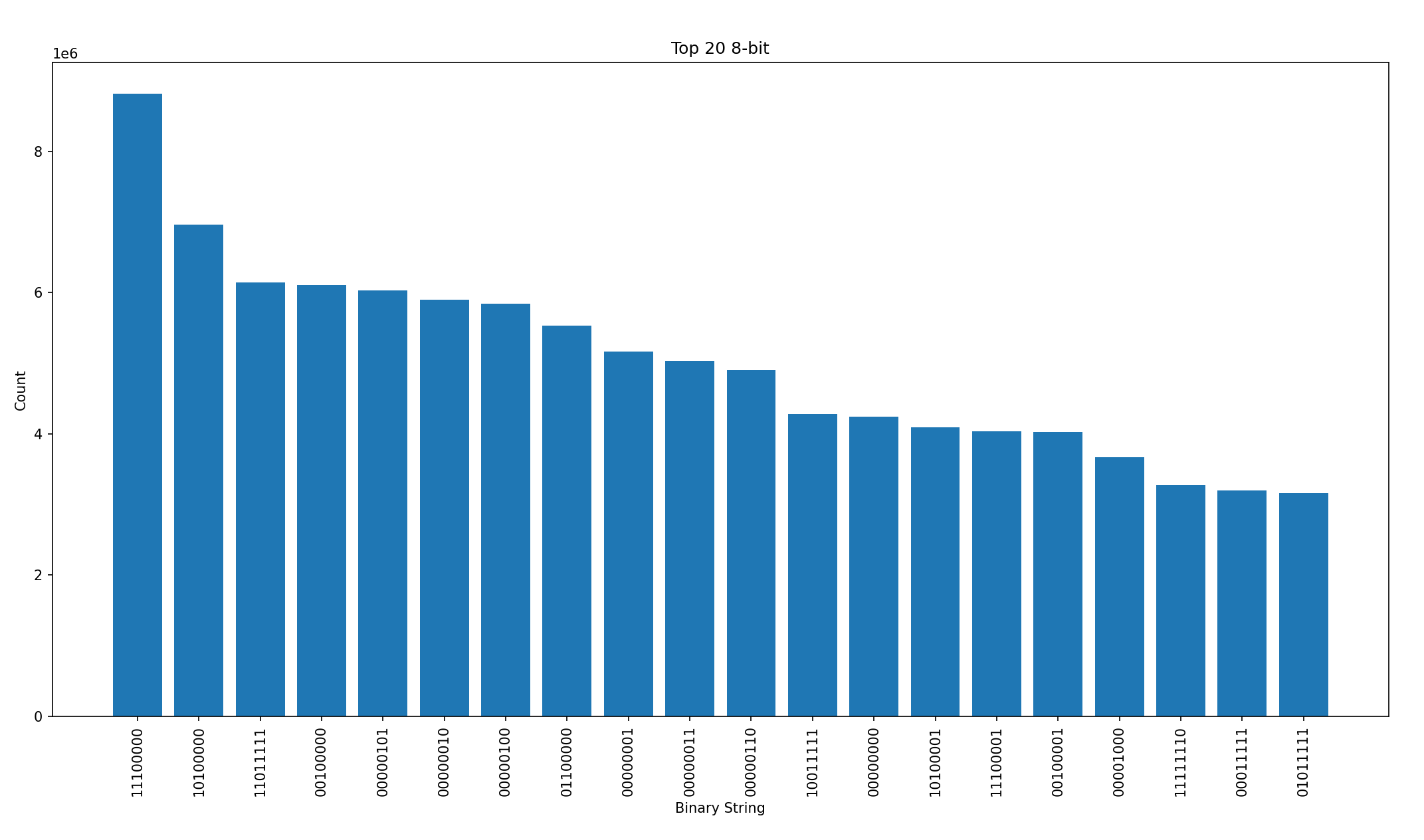
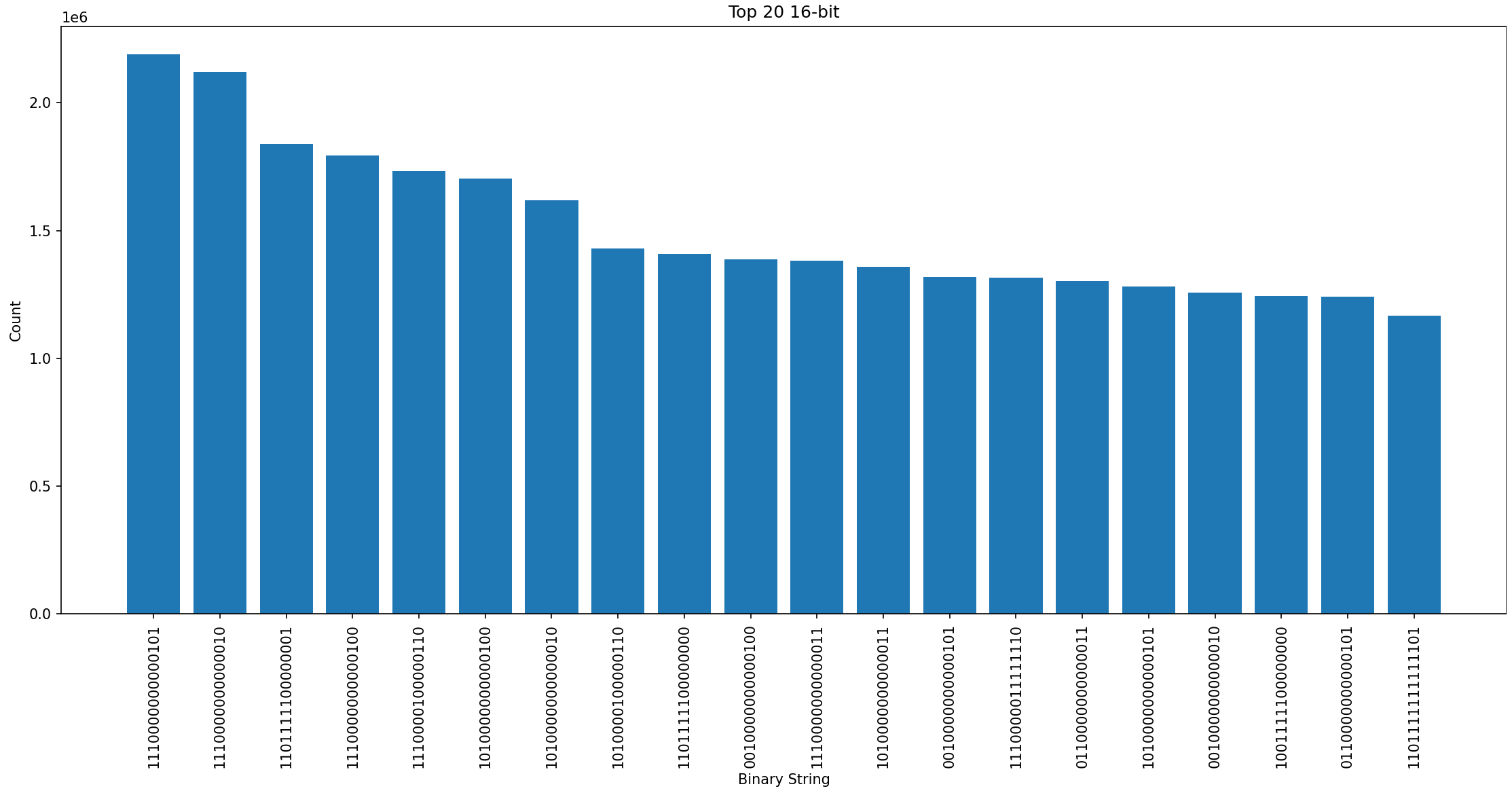
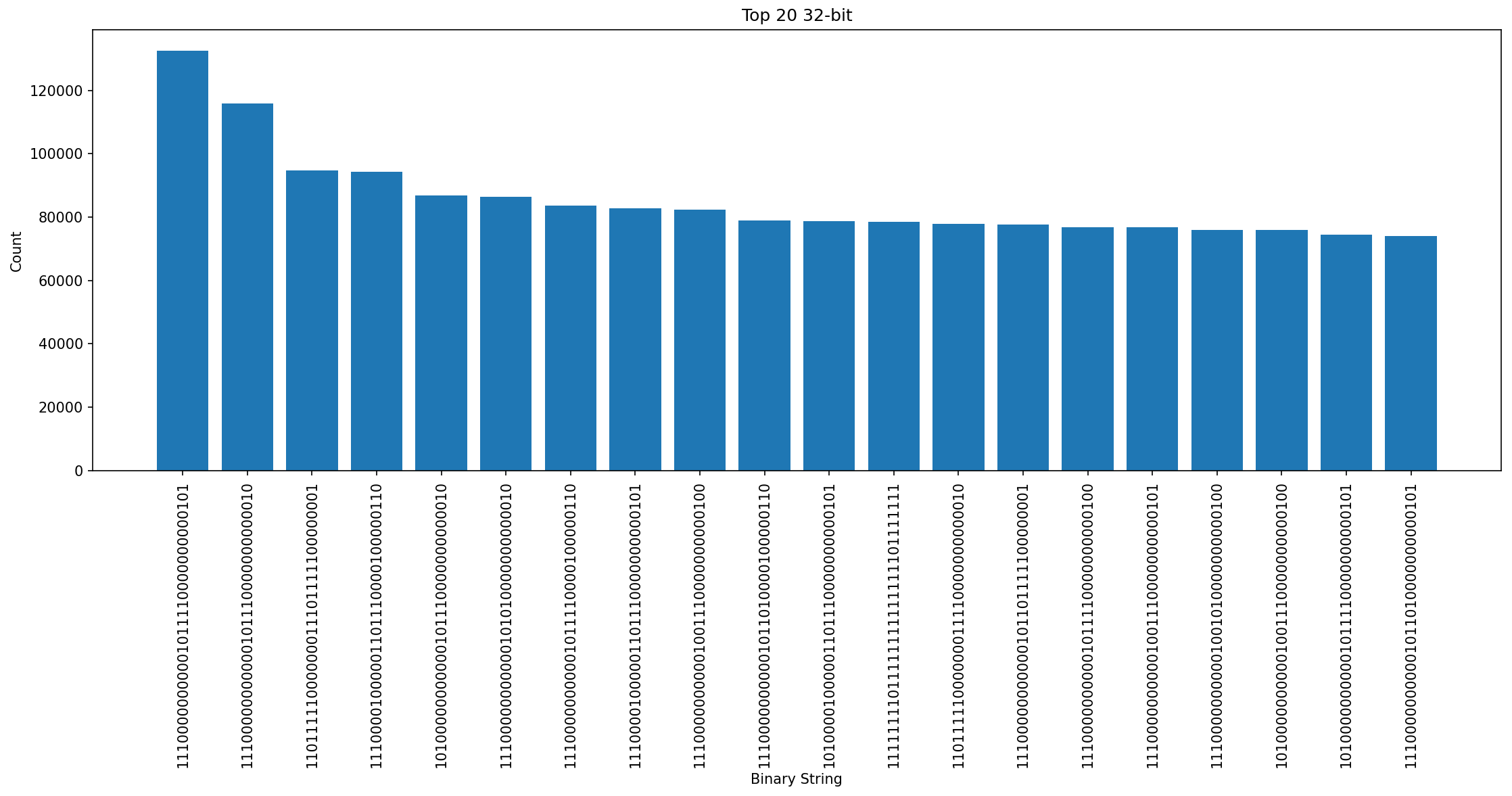
First, I tried replacing the top 20 64 bit sequences with 8 bit char placeholders, and that was a 2mb loss, which was strange, but i suppose there are few repetitions of 64 values, it has to be somewhat rare
I tried again with the top 80 32-bit values, represented by a two digit num, so 4 bytes to 2. This worked out alot better, with 62mb lost, dropping us 0.2gb total
Now to compare against the baseline, I zipped the original text file I made, then my compressed one. the Compressed zip file is 4-5% smaller, and could be even smaller if I pursued the diminishing returns in tokenization, but im just surprised my extra compression is better than pure zip, considering how optimized and mature zip is in comparision.
Neuralink already has 200x compression, buts its really, really lossy.
Some graphs from @mikaelhaji show the intense noise that supports the no 200x compression claim:
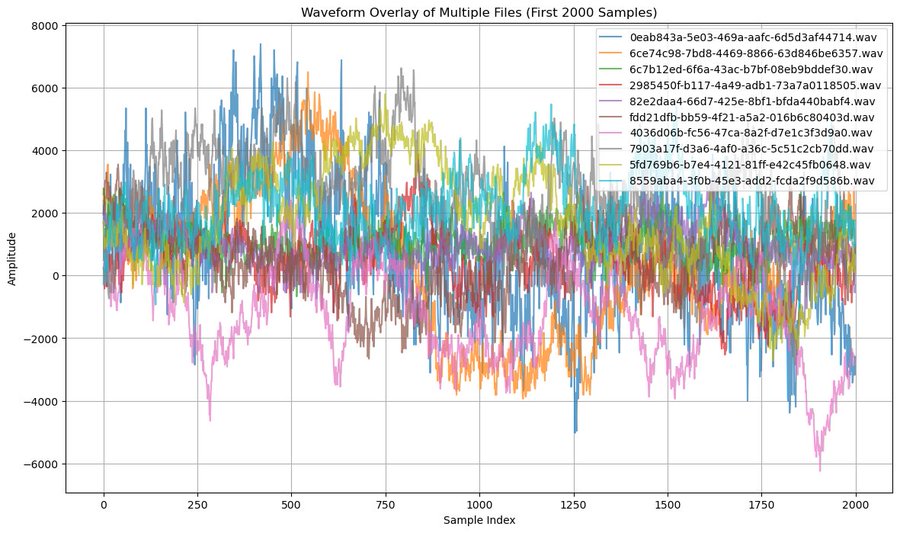
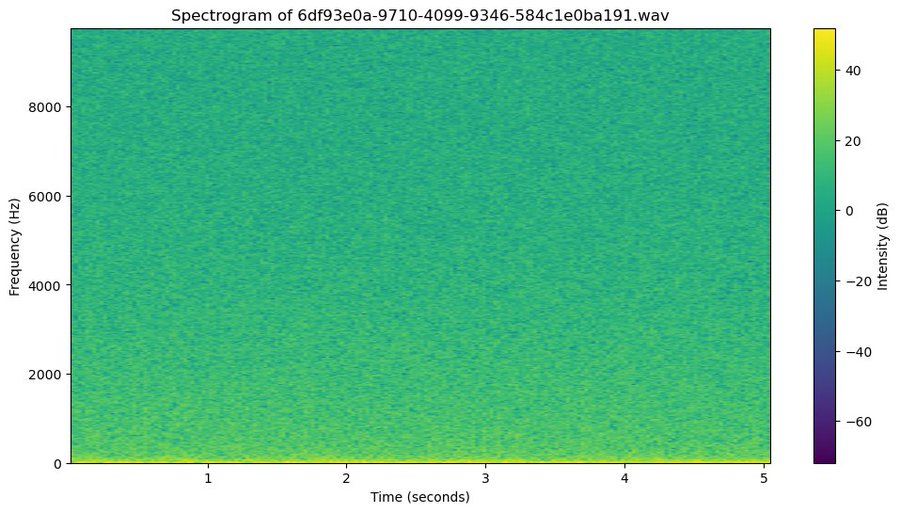
Lots of noise combined with extreme values is a great way to be incompressible, and theres a little bit of signal in lots of noise.
Theres a couple ways to get it:
overall, they want the lossless data for something, even though lossy is good enough
Some random conspiracy level thoughts about why this challenge does what it does: